
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- anomaly detection
- AnoGAN
- ubuntu pipe
- git commit
- ubuntu grep
- unsupervised learning
- AWS
- 말해보시개 딥러닝
- ubuntu zsh
- aws rds
- pix2pix
- 말해보시개 Linux
- autoencoder
- AWS Certificate
- AWS EC2
- DCGAN
- F-AnoGAN
- EC2
- ubuntu 명령어
- ubuntu mount
- Image to image translation
- linux
- gan
- CycleGAN
- bash 명령어
- docker
- ubuntu
- 쏴아리 딥러닝
- git log
- bash vs zsh
- Today
- Total
쏴아리의 딥러닝 스터디
Enhanced Deep Residual Networks for Single Image Super-Resolution(CVPR 2017) 본문
Enhanced Deep Residual Networks for Single Image Super-Resolution(CVPR 2017)
말해보시개 2021. 9. 30. 23:59Enhanced Deep Residual Networks for Single Image Super-Resolution(CVPR 2017)

Abstract
최근 super-resolution 관련 연구들은 deep convolutional network를 개발하여 진보하고 있으며, 특히 residual learning technique이 큰 성능 향상에 기여하였습니다.
본 연구에서는 enhanced deep super-resolution network(EDSR)을 제안합니다.
- model 성능이 향상된 이유는 conventional residual networks의 불필요한 modules를 제거하여 최적화 했기 때문입니다.
또한 본 연구에서는 multi-scale deep super-resolution system(MDSR)과 하나의 모델에서 다양한 upscaling factors의 images를 재구성하는 훈련방법을 제안합니다.
제안된 방법론은 benchmark datasets에서 state-of-the art methods를 능가하는 성능을 보여주었고 NTIRE2017 Super-Resolution Challenge에서 우승하였습니다.
1. Introduction
최근 deep neural networks는 Super Resolution 문제에서 peak signal to noise ratio(PSNR)기준 상당한 성능 향상을 이루어 냈습니다. 하지만, architecture optimality 측면에서 한계점지 존재합니다.
- 첫째, reconstruction 성능이 사소한 architectural 변화에 민감합니다.
- 둘째, 대부분의 Super Resolution 알고리즘은 다른 scale factors를 가진 super resolution을 독립적인 문제로 취급하고, 다른 scale간 super resolution의 상호 관련있는 요소를 고려하지 않습니다.
예외적으로, VDSR이 여러 scale간 super-resolution을 하나의 network로 취급할 수 있습니다.
- multiple scales을 갖는 VDSR을 학습하는 것은 scale-specific 훈련보다 상당한 성능을 boost 할 수 있고, 이는 scale-specific models들의 redundancy를 암시합니다.
- 하지만, VSDR style architecture는 bicubic interpolated image를 입력하기를 요구하기 때문에 scale-specific upsampling의 architecture와 비교하여 큰 computation time과 memory를 요구한다는 한계점이 있습니다.
SRResnet이 이러한 time and memory issue를 성공적으로 해결하였지만 ResNet architecture를 크게 수정하지 않고 그대로 사용하였다는 한계점이 있습니다.
- Original Resnet은 higher level computer vision problems(image classification and detection)을 해결하기 위한 모델입니다.
- 이를 super-resolution과 같은 low-level problem에 직접 적용하는 것은 suboptimal일 수 있습니다.
이러한 문제를 해결하기 위해 본 연구에서는 다음과 같이 모델을 수정하였습니다.
- 첫째, SRResNet architecture를 기반으로 하여 불필요한 modules을 제거하여 network architecture를 simplify 하였습니다.
- 수정된 scheme이 더 좋은 결과를 보여줌을 실험적으로 확인하였습니다.
- 둘째, 다른 scale에서 훈련된 model로부터 knowledge transfer하는 model training 방법을 연구하였습니다.
- scale-independent information을 활용하기 위해 low-scale models로부터 pre-trained된 high-scale model을 훈련하였습니다.
- 셋째, 다른 scales간 대부분의 parameters를 공유하는 새로운 multi-scale architecture를 제안하였습니다.
- proposed multi-scale model은 multiple single-scale models에 비해 상당히 적은 parameters만을 활용하지만, 그에 필적하는 성능을 보여줍니다.
본 연구에서는 standard benchmark dataset과 DIV2K dataset에서 모델을 평가하였고, proposed single- and multi-scale super-resolution networks가 state-of-the-art performance를 보여주었습니다.
또한 proposed method는 NTIRE 2017 Super-Resolution Challenge에서 각각 1등, 2등을 차지하였습니다.
2. Related Works
super-resolution problem을 해결하기 위한 초기 접근 방법은 sampling theory에 기반한 interpolation 기술들입니다.
- 이러한 방법들은 detailed, realistic textures를 예측하는데 한계점이 존재합니다.
이후로 Low Resolution-High Resolution image pairs간 mapping function을 학습하는 고도화된 연구들이 이루어졌습니다.
- 최근 deep neural network가 super resolution에 적용되어 큰 성능 향상을 이루어 냈고, 특히, residual network를 적용하여 더 우수한 성능을 달성하였습니다.
deep learning based super-resolution algorithms는 다음과 같이 구분됩니다.
-
- network에 입력하기 전에 bicubic interpolation을 통해 input image를 upsampling합니다.
- input image를 그대로 network에 입력하여 network의 가장 뒷부분에 upsampling module이 upsampling을 수행합니다.
- features의 size를 감소시킬 수 있기 때문에 model capacity를 잃지 않고 상당한 computation을 줄일 수 있습니다.
- 하지만, 이러한 접근방법은 multi-scale problem을 하나의 framework으로 다룰 수 없다는 단점이 존재합니다.
본 연구에서는 multiscale traning과 computational efficiency의 딜레마를 해결하기 위하여, 각 scale간 inter-relation을 활용하고 효율적인 multi-scale 모델을 제안합니다.
3. Proposed Methods
3.1. Residual blocks
최근 residual networks가 low-level 부터 high-level tasks의 computer vision 문제에서 훌륭한 성능을 보여주었습니다.
SRResNet은 ResNet architecture를 super-resolution 문제에 성공적으로 적용한 연구로, 본 연구에서는 더 좋은 ResNet structure를 활용하여 성능을 향상 시켰습니다.
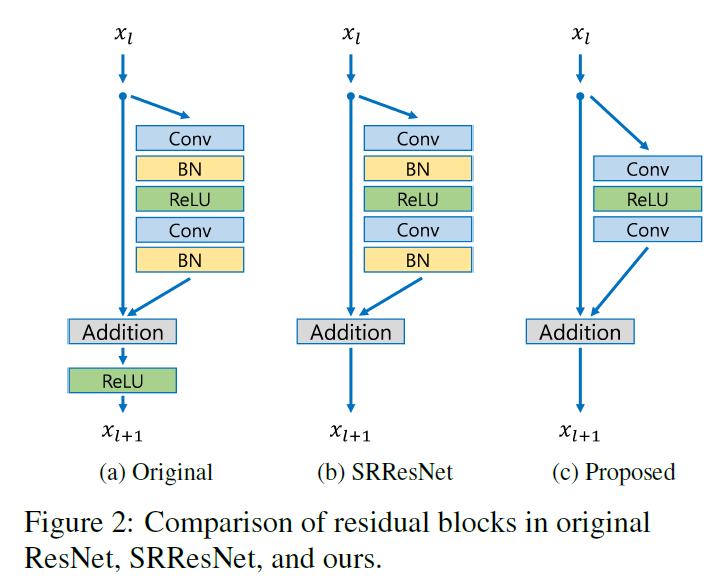
Figure 2는 Original ResNet, SRResNet, 제안모델의 building block을 비교합니다.
본 연구에서는 batch normalization layer를 제거 하였습니다.
- batch normalization layers를 features를 normalize하여 network의 flexibility range를 제거합니다. batch normalization layers를 제거 하는 것이 성능을 크게 향상 시킬 수 있다는 것을 Section 4에서 실험적으로 확인하였습니다.
- 또한 batch normalization layers가 앞의 convolutional layer와 같은 양의 메모리를 사용하기 때문에, GPU 메모리 또한 상당히 감소 시킬 수 있습니다.
결과적으로, 본 연구에서는 더 적은 computational resources로 전통적인 ResNet structure보다 더 큰 모델을 build하여 더 향상된 성능을 달성하였습니다.
3.2. Single-scale model
network model의 성능을 향상시키기 위한 가장 좋은 방법은 parameters의 수를 증가시키는 것입니다. 하지만, 특정 수준 이상으로 feature maps의 수를 증가시키는 것은 training procedure를 numerically unstable하게 만들 수 있습니다.
본 연구에서는 factor 0.1을 갖는 residual scaling을 채택하여 이 문제를 해결하였습니다.
- 각 residual block에서 constant scaling layers는 마지막 convolution layers 뒤에 존재하고, 이 모듈은 많은 수의 filter를 사용할 때 training procedure를 굉장히 stabilize하게 합니다.
본 연구에서는 baseline(single-scale) model을 Fi 2에 있는 proposed residual block으로 구성하였습니다.
- 구조는 SRResNet과 유사하지만, ReLU activation layer가 residual blocks에 없습니다.
- 또한 baseline model은 오직 각 convolution layer에서 64 feature maps만 사용하기 때문에 residual scaling layers를 갖지 않습니다.
- final single-scale model(EDSR)에서는 baseline model을 확장하여, B=32, F=256, scaling factor 0.1 을 셋팅 하여 Fig. 3과 같이 아키텍처를 구성하였습니다.

upscaling factor x3, x4를 위한 model을 훈련할 때, model parameters를 pre-trained x2 network로 initialize 하였습니다.
- Fig. 4에 기술된 것 처럼 이러한 pre-training strategy는 훈련을 가속화하고 final performance를 더 향상시킵니다.
- upscaling x4를 위하여, pre-trained scale x2 model(파란색)를 사용하였고, 훈련은 random initialization(초록색)보다 더 빠른 시간에 수렴하였습니다.

3.3. Multi-scale model
Fig. 4에서 발견한 것 처럼, multiple scales에서의 suiper-resolution은 상호 연관된 tasks임을 알 수 있습니다.
- 본 연구에서는 이 아이디어를 통해 VDSR에서와 유사하게, inter-scale correlation의 advantage를 취득하는 multi-scale architecture를 구성하였습니다.
- Fig. 5와 같이 our baseline(multi-scale) models을 single main branch with B =16 residual blocks를 갖도록 하여 parameters가 다른 scales와 공유되도록 하였습니다.

multi-scale 아키텍처에서, multiple scales에서의 super-resolution을 처리하기 위한 scale specific processing 모듈을 도입하였습니다.
- 첫째, different scales의 input images variance를 감소시키기 위하여, pre-processing modules가 head of networks에 위치합니다.
- 각 pre-processing module은 two residual blocks woth 5 x 5 kernels로 구성되어있습니다.
- pre-processing modules를 위한 larger kernels를 채택함으로써, larger receptive field가 networks의 early stages에 covered되기 때문에, scale-specific part를 shallow하게 유지할 수 있습니다.
- multi-scale model의 마지막에서, multi-scale reconstruction을 처리하기 위해 scale-specific upsamping modules가 parallel하게 위치합니다.
- our final multi-scale model(MDSR)은 B= 80, F=64로 이루어져 있습니다.
- 3가지 다른 scales을 갖는 single-scale baseline models가 1.5M parameters로 총 4.5M을 갖는 반면, our baseline multi-scale model은 3.2 million parameters만을 갖게 됩니다.
- 그럼에도 불구하고 multi-scale model은 single-scale model과 필적하는 성능을 보여주었습니다.
- 게다가, our multi-scale model은 depth관점에서 더 확장성이 있다는 장점이 있습니다.
- our final MDSR은 baseline multi-scale model과 비교하여 5배의 깊이를 갖지만, residual blocks가 scale-specific part보다 더 가볍기 때문에 오직 2.5배의 parameters만 필요합니다.
MDSR은 scale specific EDSR와 상응하는 성능을 보여주고, 세부적인 성능 비교는 Table 2와 3에서 확인 가능합니다.
4. Experiments
4.1. Datasets
DIV2K dataset과 standard bench mark datasets(Set5, Set14, B100, Urban100)을 활용하였습니다.
- DIV2K: 800 training images, 100 validation images, 100 test images.
- 본 연구에서는 100 validation images를 활용하여 성능 평가 하였습니다(100 test images의 ground truth는 공개되지 않음)
4.2. Training Details
Hyper Parameters & Data Augmentation & Data Pre-processing
- 학습을 위해, HR patches와 대응되는 LR image로 부터 48*48 size의 RGB input patches를 사용하였습니다.
- 훈련 데이터를 random horizontal flips와 90 rotations로 augment 하였습니다.
- DIV2K dataset의 RGB 값의 평균을 빼어서 모든 이미지를 전처리 하였습니다.
- ADAM optimizer $\beta_1=0.09,\beta_2=0.999,\epsilon=10^{-8}$를 활용하여 최적화 하였습니다.
- minibatch size를 16으로 셋팅하였습니다.
- learning rate를 $10^{-4}$로 초기화 하였고 각 $2*10^{5}$ minibatch update마다 절반씩 감소시켰습니다.
single-scale models(EDSR)
- 3.2절에 기술된 바와 같이 네트워크를 훈련하였습니다.
- x2 model is trained from scratch
- x2 model이 수렴한 이후, 다른 scales를 위한 model의 pretrained로 활용하였습니다.
multi-scale model(MDSR)
- 각 업데이트 마다 randomly selected scale among x2,x3,x4 miniibatch를 구성하였습니다.
- 오직 선택된 scale과 대응되는 modules가 enabled and updated 됩니다.
- 따라서, 선택되지 않은 scales의 scale specific residual blocks와 upsampling modules는 enabled되거나 updated되지 않습니다.
Loss function
- L2 대신에 L1을 활용하여 networks를 학습하였습니다.
- L2를 최소화 하는 것은 PSNR을 maximize하기 떄문에 일반적으로 선호되지만, 실험에 따라서 L1 loss가 L2보다 더 잘 수렴하는 것을 실증적으로 확인하였습니다.
- 관련된 비교실험은 4.4절에 기술되어있습니다.
Torch Framework로 proposed network를 구현하였고, NVIDIA Titan X GPUs를 활용하여 훈련하였습니다.
4.3. Geometric Self-ensemble
our model의 잠재적인 performance 최대화를 위하여, self-ensemble strategy를 채택하였습니다.
- test time동안, input image $I^{LR}$을 flip and rotate하여 7개의 augmented input을 생성합니다.
- 자기자신을 포함한 총 8개의 augmented images를 활용하여 대응하는 super-resolved images를 생성합니다.
- output images를 original geometry로 inverse transform 한 뒤, 모든 output의 평균 값을 최종 output으로 선정합니다.
이러한 self-ensemble method는 추가적인 separate models의 훈련을 필요로 하지 않다는 점에 있어서 다른 ensemble 전략보다 이점이 있습니다.
- 또한 model size나 훈련시간이 중요할 때 이점이 있습니다.
- 이 self-ensemble strategy가 total number of parameters는 똑같이 유지하면서도, 개별적인 훈련모델을 요구하는 전통적인 ensemble method와 비교하여 거의 같은 수준의 성능 향상을 이뤄낼 수 있습니다.
- 본 논문에서는 self-ensemble을 '+' postfix로 명명하였습니다(EDSR+/MDSR+)
4.4. Evaluation on DIV2K Dataset
SRResNet 부터, 점진적으로 다양한 setting을 변화시키며 ablation test를 수행하였습니다.
- loss function을 L2에서 L1으로 변경하였고, network architecture를 이전에 기술한 바와 같이 변경하였습니다(Table 1에 요약되어있습니다.)

Evaluation은 DIV2K validation set의 10 images에 대해 PSNR, SSIM 기준으로 수행되었습니다.
Table 2는 정량적 평가 결과를 정리한 것입니다.
- L1으로 훈련된 SRResNet은 L2로 훈련된 original과 비교하여 모든 측면에 비해 더 좋은 성능을 보여줍니다.
- network의 수정은 훨씬 더 큰 성능 향상을 보여줍니다.
- geometric self-ensemble technique을 적용한 EDSR+, MDSR+은 상당한 성능 향상을 보여줍니다.

4.5. Benchmark Results
public benchmark datasets에서의 정량적 평가 결과는 Table 3에 기술되어있습니다.
- EDSR, MDSR는 다른 모델들과 비교하여 상당한 성능 향상을 이루어 냈으며, self-ensemble을 수행 했을 때 성능향상이 더 컸습니다.

정성적 결과는 Fig. 6에 기술되어있습니다.
- proposed models는 성공적으로 detailed textures와 HR images의 edges를 재구성하였고, 다른 모델과 비교하여 SR output이 눈으로 보았을 때 더 좋은 결과를 보여주었습니다.

5. NTIRE2017 SR Challenge
NTIRE2017 Super-Resolution Challenge의 목적은 최고의 PSNR을 갖기위한 single image super-resolution system을 개발하는 것입니다.
- challenge에는 각각 세개의 downsample scales(x2,x3,x4)를 갖는 다른 degraders(bicubic, unknown) 2개의 track으로 구성되어있습니다.
- unknown track의 input image는 downscaled와 severe blurring이 함께 있어 더욱 robust mechanisms을 요구합니다.
- unknown downsampling track의 결과는 Fig. 7에 기술되어있습니다.
- EDSR+와 MDSR+는 first, second places에서 각각 우승 하였고 그 결과는 Table 4에 기술되어있습니다.


6. Conclusion
본 연구에서는 enhanced super-resolution을 제안하였습니다.
- 전통적인 ResNet architecture에서 불필요한 module들을 제거하였고, single-scale model은 state-of-the art performance를 달성하였습니다.
또한, model size와 training time을 감소시키기 위한 multi-scale super-resolution network를 개발하였고, single-scale SR모델과 상응하는 성능을 보여주었습니다.
- scale-dependent modules와 shared main network를 갖고 효과적으로 various scales를 하나의 framework로 대응할 수 있습니다.
our proposed single-scale and multi-scale models는 DIV2K와 standard benchmark datasets에서 top ranks를 달성하였습니다.

같이 보시면 좋아요.
2021.07.18 - [Image Generation] - “Zero-Shot” Super-Resolution Using Deep Internal Learning(2018)
2021.09.11 - [Image Generation] - Meta-Transfer Learning for Zero-Shot Super-Resolution(CVPR 2020)
포스팅 내용이 도움이 되었나요? 공감과 댓글은 큰 힘이 됩니다!



